

Dossier | Les intelligences artificielles génératives : l'envers du décor
Des Large Language Models (LLMs) pour les sciences sociales


ChatGPT est l'incarnation d'une véritable révolution méthodologique pour la recherche en sciences sociales, dont la matière principale est celle du discours. Quels impacts sur la fiabilité des travaux ? La formation des chercheurs ?
Article de Christophe Bénavent, professeur en sciences de gestion à l'Université Paris Dauphine - PSL, membre du laboratoire DRM.
Les grands modèles de langages ont trouvé dans le grand public une incarnation, celle de ChatGPT, qui cristallise un débat passionné, celui du bien et du mal, des bienfaits et des risques. Nous ne nous en mêlons pas, et nous nous limiterons à un seul objet, celui de ces implications pour la recherche en sciences sociales, dont la matière principale est celle du discours : celui des politiques consciencieusement retranscrit, celui des médias, le discours populaire et vernaculaire des réseaux sociaux et des avis de consommateurs, toutes les archives du net, les numérisations des bibliothèques, les bases de données de brevets, pour en donner des exemples évidents.
Une croissance exponentielle
C’est une révolution méthodologique qui s’engage, et qui n’a pas attendu les LLM. Cette révolution se développe depuis de nombreuses années, profitant des développements de la linguistique computationnelle et de la mise à disposition de ces grandes bases de données. Elle se traduit par l’évolution du nombre de citations qui emploient ces méthodes.
Après une première phase d’intérêt pour la thématique qui semble stagner autour de 2010, on observe depuis 2015 une croissance exponentielle. On peut raisonnablement s’attendre à ce que cette évolution se renforce avec la conjugaison de la disponibilité des données, la performance des techniques et, c’est essentiel, la facilité d’utilisation de ces méthodes. Avec les Transformers et leurs mises à l’échelle précipitée, la performance connaît un véritable bond en avant qui risque d’accentuer cette évolution.
Figure 1 : évolution des publications utilisant du NLP dans diverses sciences sociales
En réalité, les méthodes employées restent encore largement fondées sur des méthodes de dictionnaires, ou des méthodes dites de topics. Ce n’est que depuis quelques années que les embeddings - cette idée d’encoder le texte sous la forme de vecteurs de grande dimension, sont véritablement mis en œuvre.
Les grands modèles de langage n’ont pas surgi brutalement, des étapes et le développement technologiques en ont forgé longuement l’émergence. Ils s’enracinent dans une conception distributionnelle du langage qui remonte à Zipf ou à Fifth, c'est-à-dire aux années 30.
Cette approche a d’ailleurs trouvé en 1963 une sorte d’aboutissement avec l’analyse factorielle des correspondances qui a été développée notamment pour analyser le lexique dans les textes. Compter les mots, calculer leur cooccurrence a été longtemps le fondement de l’analyse sémantique.
L’aboutissement de cette perspective statistique est sans doute la formulation du modèle probabiliste de Blei en 2003, appelée LDA pour Latent Dirichlet Analysis, dont l’idée centrale est une hypothèse de distribution des mots et des sujets dans un corpus de texte. Ce premier modèle a stimulé la conception d’autres variantes autorisant des hiérarchies de thématiques, leurs possibles corrélations, l’influence de variables externes qui modulent la prévalence; ils deviennent d’usage courant.
Au cours de la première décade du XXIᵉ siècle, un ensemble d’innovations émergent et particulièrement le développement d’outils d’annotation permettant d’identifier, au niveau du mot ou de l’expression, leur nature morphosyntaxique (Part of Speech), et leurs relations syntaxiques, mais aussi de reconnaître de catégoriser des entités nommées. Pour ne citer qu’un des outils, qui joue un rôle central dans l’écosystème, la première version de CoreNLP (Stanford) est apparue en 2009.
“Le modèle Word2Vec publié en 2013 marque un tournant, et peut-être pensé comme le germe des grands modèles de langage qui se disputent l’actualité.”
Le modèle Word2Vec publié en 2013 marque un tournant, et peut-être pensé comme le germe des grands modèles de langage qui se disputent l’actualité. L’idée au fond est assez simple :, elle consiste à représenter les unités (les mots) par des vecteurs définis en grande dimension (de 100 à 1000 pour donner une idée de l’échelle), de telle manière à ce que leur direction reflète leur distribution.
Deux mots souvent employés ensemble (dans une même série de tokens) auront un angle faible et une similarité élevée (le cosinus de l’angle formé en est la mesure). Et si on peut vectoriser les mots, on peut le faire aussi pour les phrases, dont le vecteur sera la moyenne des vecteurs mots qui le constitue. On pourra aussi créer des concepts, qui seront les moyennes des mots qui leur correspondent, et l’on pourra aisément comparer les textes pour en construire des typologies ; ou comparer des concepts à des textes, pour en détecter la présence.
Cette méthode peut aussi être comprise comme une compression de l’information. En effet, si pour représenter un texte, on avait l’habitude de le représenter sous la forme d’un tableau contenant autant de lignes que de documents et de colonnes que la taille du vocabulaire (sachant que dans un corpus courant ce dernier peut avoir facilement une taille de plusieurs dizaines de milliers de mots), la méthode revient à concentrer l’information dans un millier de colonnes.
Ces vecteurs, couramment appelés embeddings en anglais et, de manière juste et poétique, plongements en français, restent cependant des approches en sac de mots, qui ignore l’ordre des mots et leurs interdépendances (syntaxiques et coréférences).
“En 2017, l’invention des matrices d’attention, qui donne naissance à la classe hégémonique des modèles dit Transformers, va précipiter le développement de ces modèles”
En 2017, une autre invention va précipiter le développement de ces modèles : l’invention des matrices d’attention, qui donne naissance à la classe hégémonique des modèles dit Transformers, dont BERT est certainement le plus connu. Ces modèles de représentations du langage sont depuis entraînés à différentes tâches, et surtout sur des corpus aux échelles inédites, passant de quelques dizaines de millions de paramètres à plusieurs centaines de milliards.
En quelques années, une nouvelle classe de modèles est apparue, celle de modèles fondationnels couvrant un très grand espace de langage, qui forment le socle sur lequel peuvent se développer de multiples applications spécifiques par des entraînements dédiés.
Les solutions amenées par la science et le marché connaissent toujours une sorte de révolution précambrienne dont témoigne le nombre de modèles hébergés par Hugging Face, qui se trouve désormais au centre d’un nouvel écosystème.
La première voie, celle d’OpenAI, est un modèle centralisé où le calcul est effectué sur la plateforme principale, via très certainement une multiplicité d’applications développées par des tiers. Le modèle de revenu de ces plateformes est clairement celui du Saas, la rémunération venant de la quantité de données traitées. Le problème posé est celui de grands comptes qui ne souhaitent pas voir leurs données sortir de l’enceinte de leurs organisations pour nourrir ces modèles.
La seconde voie, ouverte par Meta avec Llama, mais aussi par MistralAI, est celui de modèles partiellement ouverts (seuls les poids sont ouverts) qui par des méthodes d’ajustements sur des corpus spécifiques permet d’en améliorer la performance pour des tâches spécifiques (Q&A, chat, résumés…).
L'annotation des corpus au coeur de l'usage
Pour les sciences sociales, ces inventions ont un caractère fondamental, en permettant d’exécuter une tâche essentielle, celle d’annoter des mots, des phrases, des documents, par toutes sortes de concepts. Ce que le chercheur faisait avec son Stabilo, et les notes en marge des documents qu’il traitait (compte-rendu historique, retranscription d’entretien, résumés d’articles scientifiques, brevets, discours), la machine est désormais en mesure de le faire à grande échelle, permettant de quantifier ce qui était qualitatif, et d’en observer l'évolution au cours du temps et à travers l’espace.
Cet usage spécifique s’ajoute à la pratique plus interactive des IAG : faciliter l’écriture, générer des fragments de codes, résumer des documents et améliorer le quotidien des chercheurs en faisant faire des gains de productivité sur certaines tâches.
Pour les sciences sociales, l’usage spécifique consiste à analyser des corpus qui peuvent contenir plusieurs millions de documents, en les annotant. La tâche reine est celle de la possibilité d’annoter le contenu des textes par des approches de Zero Shot Classification, qui consiste à inférer les probabilités que des catégories soient associées à un texte, sans apprentissage préalable de la notion que l’on cherche à catégoriser.
Arrêtons-nous un instant sur la question des corpus en donnant quelques exemples :
- Le discours des hommes politiques et de leurs assemblées
- La collection des brevets, des publications
- Les historiques financiers, leurs news
- Des bibliothèques, corpus de roman et historiographiques
- Des conversations, qu’elles soient saisies dans des forums ou transcriptions de campagne d’entretien semi-directive massive.
- Des programmes de télévision
- Des corpus publicitaires
- Des avis de consommateurs,
- Des flux de messages provenant des réseaux sociaux
- Des bases de données ouvertes telles que Open Food Fact qui recense près d’un million de produits alimentaires avec de nombreux champs purement textuels, ou Discogs qui rassemble près de 14 millions d’éditions phonographiques..
Pour comprendre de manière immédiate l’importance de l’annotation, imaginons que l’on s’intéresse à la question sociale des chauffeurs Uber, et que l’on ait constitué un corpus spécifique, par exemple, les 100 000 posts du forum Sam VTC. La première question qu’on peut se poser est d’identifier les acteurs (personne et organisations, les lieux et les événements, pour ensuite examiner leurs cooccurrences et la nature des relations qu’ils entretiennent). Cette tâche est connue sous la dénomination de “reconnaissance des entités nommées” (NER), elle ne nécessite pas forcément de LLM et peut être réalisée avec des méthodes de classification automatiques disponibles depuis une ou deux décades : un modèle de machine-learning est entraîné sur un corpus annoté le plus souvent manuellement, certains de ces modèles étant disponibles dans des packages r ou python.
Avec les IAGs cette tâche est grandement simplifiée : un prompt bien conçu permet de réaliser cette tâche sans passer par l’épreuve d'entraînement. L’image ci-après représente le résultat de cette opération sur un fragment d’un article récent du monde, avec le modèle Llama 2 13 GB Q5, installé localement.
Figure 2 : Exemple d’annotation NER sur un article du monde et le modèle Llama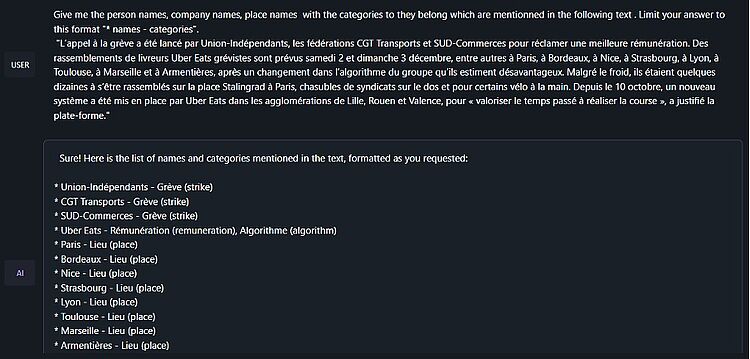
Ce rôle général est celui de l’annotation, c'est-à-dire de répondre notamment aux questions suivantes :
- Quels sont les acteurs qui se manifestent dans le texte, à quel moment, dans quels lieux et quelles circonstances? (NER)
- Quelles sont les thématiques (Topics)
- Quelles sont les argumentations ? (key word exaction)
- Quelles humeurs, sentiments, émotions (sentiment analysis)
- Quelles figures de style ?
- Quels sont les textes analogues ou similaires ?
Dans l’exemple suivant, on utilise un modèle nli-DistilRoBERTa-base pour faire de l’analyse des émotions Zero-Shot sur une très grande quantité de commentaires d’utilisateurs de logement Airbnb. La vingtaine de tags représentent les termes classiques du sentiment et des émotions auxquels on a ajouté quelques termes plus spécifiques.
En analysant les corrélations entre les probabilités que chacun de ces labels soient associés aux commentaires, on redécouvre la structure tri-polaire du sentiment. On imagine aisément comment généraliser cette approche à d’autres concepts ou catégories. Ici le LLM joue le rôle d’une sonde qui explore avec différents labels un même domaine conceptuel. Les résultats peuvent être ensuite analysés par des méthodes factorielles pour identifier les principales facettes du concept qu’on étudie et pouvoir le quantifier. C’est une nouvelle perspective de la mesure en science sociale qui s’esquisse.
Figure 3 : ZSC de 20 labels d’émotion et ACP de leurs corrélations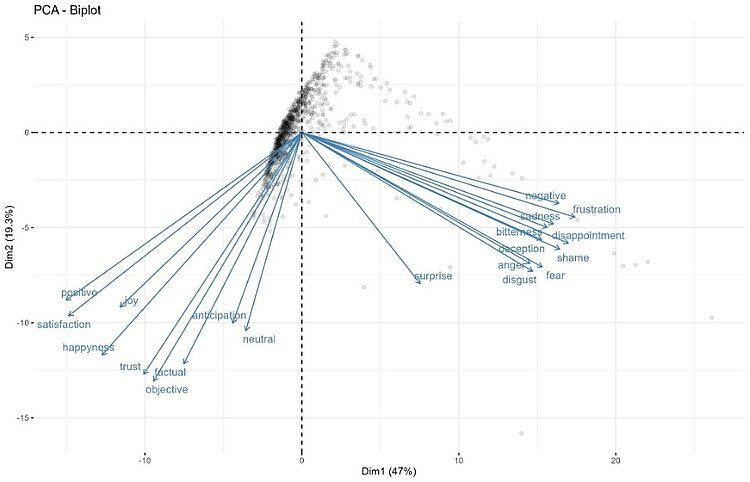
Les LLMs en sciences sociales : des enjeux techniques, scientifiques et sociaux
Pour la recherche en sciences sociales, les LLM offrent une opportunité majeure de traiter des corpus à une échelle inégalée. Naturellement, cette promesse n’est pas sans enjeu : ils sont à la fois techniques, scientifiques et sociaux et vont nécessiter la construction de nouveaux protocoles méthodologiques.
Un enjeu économique
Même s’il n’est pas demandé à l’économiste ou à l’historien de développer son propre modèle général de langage, mais d’exploiter et d’ajuster des modèles généraux à son propre usage, la question du coût se pose de manière immédiate. L’offre d’OpenAI est de l’ordre de 10$ le million de tokens (Input), ce qui semble peu élevé, mais se multiplie. Pour donner un ordre d’idée, le corpus de “vie publique”, qui comprend 150 000 textes (des communiquées aux longues interviews) représente un volume de 187 millions de mots et donc au moins le double en termes de tokens (les mots sont le plus souvent représentés par plus d’un seul token). Il faut donc compter un budget de 4000$ par annotation.
Un enjeu matériel
Chacun aura observé qu’une requête (prompt) sur ChatGPT prend plusieurs secondes pour être traitée. À grande échelle ceci signifie un traitement par lot qui pourrait prendre des heures ou des jours. L’alternative réside aujourd’hui dans l’utilisation des modèles à accès ouvert, dont l'évolution vers la recherche de taille plus raisonnable.
Ils sont d’ailleurs proposés en différentes versions qui varient en termes de nombre de paramètres (7, 13, et 70 milliards de paramètres constituant les normes actuels) et en degré de “quantization”, une technique d’arrondi des paramètres permettant d’alléger la taille des modèles. Mais là aussi, la question de la latence demeure, même si celle des coûts directs se résorbe, et pose la question des équipements nécessaires qui dépassent en puissance ce que le chercheur ordinaire connaît, surtout si les modèles doivent être ré-entrainés.
Un enjeu de formation des chercheurs
Un corollaire de l’enjeu matériel est celui des compétences. L’approche computationnelle en science sociales demande une approche moins solitaire de la recherche, et exige que les chercheurs bénéficient de compétences collectives et du soutien d’ingénieurs de recherche. L’opportunité offerte par ces technologies se paye par une technicisation élevée des méthodes de recherche. En deçà de ce soutien, il va falloir former, notamment les doctorants à des méthodes computationnelles, passant par l’apprentissage de langage comme python ou r, et à l'usage des grands packages d’analyse et de traitement du langage. Comme dans de larges pans du champ des sciences sociales, une culture qualitative s’est développée, plus qu’une question de formation, il s’agit d’un changement de culture technique.
Un enjeu méthodologique
Les réponses données par le système doivent être valides et fidèles. La reconnaissance de caractère est désormais précise à moins de 0.1 % d’erreurs, les annotateurs syntaxiques sont fidèles à 90-95 % sur des corpus standard.
Dans le cadre d’un cours de la PSL Week, en testant la capacité de ChatGPT à identifier les figures de style d’un petit corpus de slogan, publicitaire(n=400), un groupe d’étudiants bien formé en linguistique, a évalué les propositions de ChatGPT (one shot).
Résultat: une précision du modèle estimée à environ 50 %, avec certaines figures de style bien mieux identifiées que d’autres. C’est bien trop insuffisant. Au-delà du développement de méthodes d’évaluation des modèles tel que le MMLU, l’enjeu de la reproductibilité et de la réplicabilité qui s’appuie sur des data sets de référence et dont l’intérêt est de comparer sur certaines tâches, l’usage de ces méthodes en sciences sociales doit être accompagné de tests spécifiques qui permettent d’évaluer la performance sur des corpus “ naturels”.
Analyser du langage élaboré, un corpus de presse ou de textes officiels, ou du texte vernaculaire peut donner des résultats très différents. S’ajoute la question de la reproductibilité des mesures alors que les modèles de langage sont régulièrement mis à jour avec une transparence très limitée, ne serait-ce que parce que les corpus d’entraînement ne sont pas forcément connus.
Un enjeu de légitimité
Le dernier enjeu est celui de la légitimité de ces méthodes au sein de la communauté des chercheurs en sciences sociales. Celle-ci dépend de critères méthodologiques que nous venons d’évoquer, mais aussi de considérations juridiques et déontologiques. Les questions du respect des droits de propriété intellectuelle, de biais et de sécurité, de transparence, de décision automatique font l’objet de débats. La question de la régulation des techniques d’intelligence artificielle et des conditions de son exploitation, ne fait que commencer à être posée.
Vers des protocoles de mesure
Les grands modèles fondationnels, peuvent rencontrer un succès d’estime auprès du grand public, facilitant l’écriture du courrier courant ou la réponse à des questions rapides. Ils peuvent, au travers d’adaptations et d’encapsulation, rendre des services utiles à un grand nombre de professions qui travaillent le texte : traducteurs, avocats, comptables, analystes financiers, bureaucrates. Et sont déjà utiles à des professions moins honorables qui n’ont pas le souci du texte, mais ont besoin de sa prolifération, le SEO notamment et les autres professionnels de l’influence et de la désinformation.
Dans l’ensemble de ces activités, l’usage est interactif : il s’agit chaque fois de produire un texte singulier, qu’on peut façonner en variant les prompts, jusqu’à obtenir un résultat satisfaisant l’idée qu’on se fait de la question. Ceci peut stimuler la créativité, produire des textes mieux normés, mais uniques.
“Dans le cadre de modèle LLM, l’instrument de mesure est constitué de deux éléments : le modèle de langage et la formulation des prompts.”
Mais pour les sciences sociales, l’usage est différent. Il ne s’agit pas d’interagir au cas par cas, mais bien d’annoter de vastes collections de documents dans un traitement “one shot”. Dans ces domaines, les LLM doivent encore apporter la preuve de leur capacité de véridicité et de leur capacité à travailler à l’échelle. Il va falloir imaginer de nouveaux protocoles de mesures, à la manière du processus de Churchill que les chercheurs en gestion connaissent bien.
Dans le cadre de modèle LLM, l’instrument de mesure est constitué de deux éléments : le modèle de langage et la formulation des prompts. Le protocole de mesure doit donc comprendre d’abord une étape de choix et de justification du langage.
Pour traiter un corpus français, faut-il choisir FlauBERT ou CamemBERT, ou encore un modèle multilingue qui aurait cependant été entrainé sur un corpus à plus de 80 % en anglais ?
Le second élément est naturellement celui de la formulation des prompts et de leur standardisation. Multiplier les prompts similaires pour mieux saisir le concept et développer des mesures de fiabilité entre leurs réponses par des mesures de concordance peut apparaitre comme une voie intéressante, analogue à l’approche des psychométriciens qui pour saisir un trait (par exemple de personnalité) proposent différents items.
Une dernière remarque, si le texte - ce texte vertigineux produit autant par la littérature que le small talk des réseaux sociaux, la production commerciale ou la télévision - est la société, la société ne dit pas tout dans le texte. Aussi puissantes soient les techniques qui permettent de lire quantitativement ce que dit la société, il n’y a pas de technique qui écoute son silence.
Si nous sommes persuadés que les LLM vont fournir le socle des nouveaux dispositifs d’observation de la société dans ses dimensions économique, organisationnelle, historique, sociale et culturelle, et qu’il est urgent de s’y investir et de les maîtriser, nous sommes convaincus que la méthode en sciences sociales ne peut s’y limiter.
Ce contenu est publié sous licence Creative Commons ![]()
![]()
![]()
![]()
Nos articles sont publiés sous licence Creative Commons. Leur réutilisation est autorisée sous certaines conditions.
À lire aussi

Transition Écologique & Sociale
Politique industrielle et technologies bas carbone : la trajectoire chinoise
La domination chinoise dans les technologies bas-carbone est souvent présentée comme une conséquence de sa puissance manufacturière. Elle est avant...

Derrière l’image spectaculaire des crises, Anouck Adrot traque ce qui, en amont, conditionne la capacité des organisations à agir. Maîtresse de...

L’intelligence artificielle générative promet de transformer le conseil financier. Mais ses capacités réelles restent mal connues. À l’Université...