

Dossier | Les intelligences artificielles génératives : l'envers du décor
Entre réalisme et inventivité : comment cadrer les IA Génératives ?

Dall-E, ChatGPT, Midjourney... L'intelligence artificielle générative est en train de révolutionner de nombreux domaines. Comment évaluer la qualité de ces modèles ?
Article d'Alexandre Verine, doctorant au sein du LAMSADE, Université Paris Dauphine - PSL.
L'intelligence artificielle (IA) générative est en train de révolutionner de nombreux domaines, se positionnant à l'avant-garde de la technologie actuelle. Cette branche spécifique de l'IA est capable de créer automatiquement du contenu innovant, et ce, dans une variété de domaines allant au-delà de la simple génération de textes ou d'images. La famille de modèles GPT (qui sont à la base de Chat-GPT), ainsi que Dall-E et Mid Journey pour la création d'images, représentent des exemples emblématiques de cette évolution. Mais l'IA générative s'étend bien au-delà : elle englobe des systèmes comme Jukebox de OpenAI, un modèle capable de générer de la musique dans différents styles, et des modèles comme ceux développés par Atomwise et In Silico Medecine, qui se concentrent sur la génération de nouvelles structures moléculaires pour les médicaments.
“Cette capacité à assimiler et à reproduire la complexité des données d'entrée est ce qui rend ces modèles si puissants”
Ces modèles d'IA générative sont construits à partir réseaux de neurones artificiels. Ceux-ci sont d'abord exposés à un grand nombre d'exemples au sein d'un ensemble de données variées. Pour GPT-4, ces données comprennent une gigantesque gamme de textes provenant d’une multitude de sources (forums, réseaux sociaux, Wikipedia, bases de données scientifiques, archives de grands journaux...).
Le modèle apprend ensuite à reconstruire ou à générer de nouveaux contenus qui imitent ceux de son ensemble d'entraînement. Cette capacité à assimiler et à reproduire la complexité des données d'entrée est ce qui rend ces modèles si puissants. Non seulement ils apprennent les structures de base de ces données, mais ils en comprennent aussi les nuances et les variations subtiles, leur permettant de créer par la suite du contenu qui semble naturel et convaincant.
"Malgré leur sophistication, ces modèles ne sont pas capables de reproduire toutes les données observées parfaitement”
Néanmoins, ces systèmes présentent certaines limites. Bien qu'ils soient capables de traiter, d’assimiler et d’engendrer des données complexes, leur « intelligence » et leur « créativité » ne sont le reflet que de leur capacité à reproduire ce qu’ils ont observé lors de l’entraînement.
Ainsi ces modèles, malgré leur sophistication, ne sont pas capables de reproduire toutes les données observées parfaitement. En pratique, cela se traduit par un compromis entre la diversité (quand le modèle est capable de reproduire la même variété que son ensemble d’entraînement), et la qualité (quand chaque donnée produite est réaliste).
Prenons l'exemple de deux modèles populaires de génération d'images auxquels on donne la même consigne : "un enfant qui joue avec un chien". Les résultats obtenus sont significativement différents :
D’un côte, Dall-E2 produit une large gamme d'images, offrant une variété de scénarios, de différents chiens, de garçons ou de filles de divers âges.
Toutefois, ces images manquent parfois de cohérence : des anomalies peuvent parfois survenir dans le rendu des visages ou des mains , tandis que certaines scènes semblent irréalistes, allant jusqu'à montrer un chien avec une patte manquante.
Images générées par DALL-E 2 de OpenAI
- D’un autre côté, Mid Journey, modèle concurrent, s’avère capable de produire des images sans défauts visuels (ou artefacts), ni incohérences, donc nettement plus convaincantes et de meilleure qualité. Cependant, ces images plus réalistes sont en même temps souvent plus uniformes, représentant fréquemment des petits garçons aux cheveux châtains face à un chien de couleur claire, dans des situations similaires. Ces exemples illustrent les extrêmes du compromis entre qualité et diversité offerts par ces modèles d'IA générative.

Images générées par MidJourney
Consciente de cette dichotomie, la communauté de recherche en Intelligence artificielle s’intéresse au développement de modèles qui soient à la fois plus intelligents et plus expressifs. Cela implique des ressources de calcul plus importantes, des ensembles de données plus vastes et de meilleure qualité.
Cependant, il existe une approche alternative, moins idéale mais couramment utilisée : le "cherry picking" ou "picorage". Cette méthode consiste à sélectionner manuellement ou à l'aide d'un second modèle d’IA (un classifieur, par exemple) les contenus générés en fonction de leur qualité. Ce processus, connu sous le nom d'algorithme de rejet, est doublement problématique : il n'est efficace que si le modèle original est suffisamment diversifié pour produire un large éventail de contenus, et il est également très gourmand en ressources, car le modèle génératif peut être amené à produire des milliers d'exemples pour en retenir finalement un seul.
Diversité ou qualité ?
Pour répondre à ce problème, des recherches récentes permettent de mieux comprendre les éléments fondamentaux qui affectent la qualité et la diversité des modèles d'IA générative, dans l'objectif de les adapter et les améliorer (1). Ces travaux mettent en lumière des liens théoriques mais aussi pratiques entre la qualité et la diversité et la manière dont les données d'entraînement sont comparées aux données engendrées. Il devient dès lors possible d’utiliser une estimation mathématique formelle pour évaluer à la fois la qualité et la diversité des images générées.
Loin de critères subjectifs d’appréciation des contenus produits, qui ont tendance à favoriser la qualité, ces travaux permettent une évaluation objective et précise des modèles, sur la base de mesures quantifiables et reproductibles. Plus intéressant encore, les résultats de recherche permettent de régler ces modèles pour une meilleure performance à n’importe quel compromis entre qualité et diversité (2), mais aussi d’améliorer l'algorithme de rejet pour augmenter la performance des modèles sous contraintes de ressources réduites (3).
Comment expliquer qu’un modèle d’IA générative s’oriente davantage vers la diversité ou plutôt vers la qualité ?
(1) L’analyse, reliant les méthodes d'évaluation à ces aspects et les fonctions de perte minimisées par les modèles, a permis une compréhension approfondie de leurs dynamiques internes et dissipé les préjugés concernant la qualité de certains modèles : un modèle perçu comme de moindre qualité peut en fait être optimisé pour la diversité. Cette compréhension permet ainsi de choisir le modèle le plus adapté en fonction des besoins spécifiques, que l'objectif soit la diversité du contenu ou sa précision.
Régler les modèles pour une meilleure performance ou une meilleure diversité
(2) Partant de cette nouvelle compréhension, il devient possible d’élaborer d'un algorithme d'entraînement capable d'ajuster finement le compromis entre diversité et précision pour les modèles d'IA générative, indépendamment de leur architecture. Cette innovation offre une flexibilité essentielle pour des applications variées. Elle permet par exemple à des entreprises telles que MidJourney de produire des images d'une qualité exceptionnelle pour la commercialisation, tandis que dans le domaine pharmaceutique, l'algorithme peut être configuré pour générer une vaste diversité de structures moléculaires à des fins de recherche et de développement.
L'efficacité de cet algorithme a été démontrée de manière concrète avec divers jeux de données mais en particulier sur MNIST, un standard pour l'apprentissage des modèles d'IA en reconnaissance de chiffres. Trois scénarios différents ont été testés pour illustrer la capacité de l'algorithme à équilibrer diversité et qualité :
Un modèle entraîné avec pour objectif une grande diversité : Une grande diversité de chiffres est produite mais une grande partie des chiffres laisse perplexe :
Un modèle entraîné avec pour objectif un compromis équitable diversité et qualité :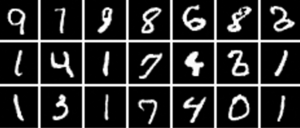
Un modèle entraîné avec pour objectif une grande qualité : Pour être capable de générer des images d’aussi bonne qualité, le modèle n’est capable de générer que des 0, 1, 6, 7 et 0. 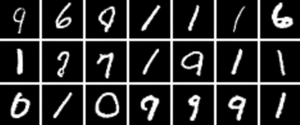
Comment assurer un bon niveau de performance sans consommer trop de ressources ?
(3) Une fois l’algorithme défini, il subsiste un défi majeur : comment s’assurer que le modèle maintienne un bon niveau de performance sans consommer trop de ressources ? Un nouveau concept permet de s’attaquer au problème, celui d’un budget défini dans l'application de l'algorithme de rejet optimisé. Plutôt que de laisser l'algorithme fonctionner sans limites, ce qui pourrait conduire à une consommation excessive de ressources, une limite stricte est imposée sur le nombre d'images qu'il peut générer avant de devoir en accepter une.
“Une méthode permet ensuite de choisir l’image qui permet de maximiser à la fois la précision et la diversité”
Ce budget, adapté aux ressources disponibles et aux exigences du projet, détermine le nombre maximal d'images que l'algorithme peut traiter. Ainsi, un budget restreint autorisant l'algorithme à évaluer seulement deux ou trois images signifie qu'il doit sélectionner la meilleure parmi ces essais limités. Un budget plus conséquent, permettant jusqu'à dix images, offre à l'algorithme une plus grande marge de manœuvre pour produire des images de qualité supérieure. Une méthode permet ensuite de choisir l’image qui permet de maximiser à la fois la précision et la diversité. Lorsque le modèle a été “paramétré” pour être diversifié (voir le point (2)), l’algorithme de rejet s’avère particulièrement efficace.
Ces récentes avancées constituent des progrès notables dans l'optimisation des modèles génératifs avec des résultats déjà applicables à divers types de génération, notamment dans les domaines des images et des structures moléculaires. Cependant, l'application de ces principes aux modèles de génération de texte représente un horizon prochain, ouvrant la voie à des avancées futures. Cette étape constitue un défi passionnant plein de challenges pour les (années) mois à venir.
Ce contenu est publié sous licence Creative Commons ![]()
![]()
![]()
![]()
Nos articles sont publiés sous licence Creative Commons. Leur réutilisation est autorisée sous certaines conditions.
À lire aussi

Transition Écologique & Sociale
Politique industrielle et technologies bas carbone : la trajectoire chinoise
La domination chinoise dans les technologies bas-carbone est souvent présentée comme une conséquence de sa puissance manufacturière. Elle est avant...

Derrière l’image spectaculaire des crises, Anouck Adrot traque ce qui, en amont, conditionne la capacité des organisations à agir. Maîtresse de...

L’intelligence artificielle générative promet de transformer le conseil financier. Mais ses capacités réelles restent mal connues. À l’Université...