

Ouvrage | Covid-19 : regards croisés sur la crise
L’intelligence artificielle au secours des gestionnaires d’actifs en période de crise
Nous expliquons sommairement comment l’intelligence artificielle (IA) peut aider les gérants d’actifs à gérer aux mieux les contextes de crise, à travers l’apprentissage par renforcement avec des réseaux profonds.
La crise de la Covid-19 est un fait unique dans notre histoire. Elle soulève de nombreuses questions économiques ainsi que de nombreuses réflexions de société. L’économie actuelle est-elle trop mondiale ? Notre système de santé est-il bien préparé à un phénomène de pandémie ? Peut-on prévoir l’impact d’un confinement sur l’économie et surtout sur les marchés boursiers ? Comment un gérant d’actif doit-il s’adapter à un tel environnement pour gérer au mieux son portefeuille ?
Nous laisserons aux spécialistes de l’économie et de la mondialisation le soin de répondre aux premières questions pour nous attacher à la problématique de l’adaptation pour les gérants financiers de cette crise inédite et spectaculaire à bien des égards. Tout d’abord, cette crise ne ressemble à nulle autre. Elle est marquée par la rapidité de la chute brutale des marchés financiers et de leur remontée toute aussi rapide. Si l’on prend comme référence le marché américain et son indice de référence le S&P 500, la chute aura été de très courte durée avec un début de baisse le 20 février, une fin le 23 mars 2020, soit 23 jours ouvrés et une chute de -35 %. Le retour au niveau initial a eu lieu le 12 août, au bout de 101 jours ouvrés. À titre de comparaison, la précédente crise financière majeure de 2008 a eu une chute 4 fois plus longue avec 97 jours ouvrés et une rémission sur environ 3 ans (780 jours ouvrés). L’éclatement de la bulle internet dans les années 2000 suit le même constat : chute de 639 jours ouvrés et remontée sur 1 242 jours ouvrés soit quasi 5 ans illustré par le graphique 1.
Graphique 1
Indice boursier S&P 500 (source : Bloomberg®)
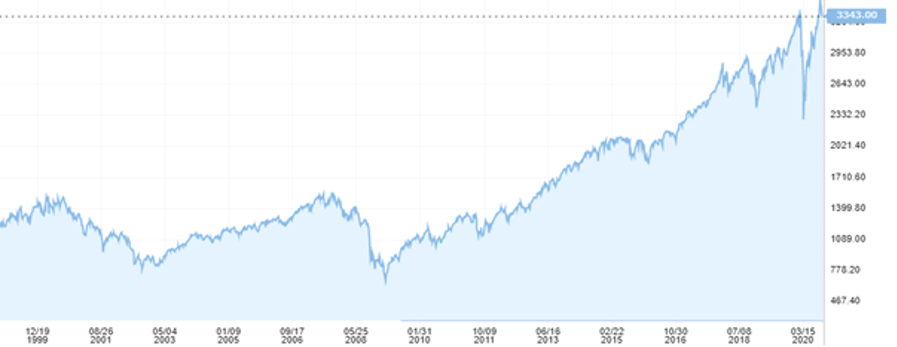
Il n’est donc pas étonnant que l’industrie de la gestion d’actifs ait soufferte de cette crise. D’une part, la chute a été tellement rapide que beaucoup de gestionnaire d’actifs n’ont pas eu le temps de réagir. Mais une fois la chute arrivée, ceux-ci ont cristallisé leur perte et n’ont pas anticipé un rebond aussi rapide. Ils ont été ainsi victime deux fois de la crise de la Covid-19 : d’une part, en ne coupant pas leurs positions suffisamment rapidement et d’autre part, en n’anticipant pas une reprise aussi rapide. À l’aune des crises précédentes, les marchés avaient mis un temps beaucoup plus long à réagir. Aussi beaucoup n’ont pas profité du rebond des marchés. Ces deux mauvaises décisions peuvent trouver leur origine dans des biais cognitifs et des facteurs émotionnels caractéristiques de l’esprit humain, comme le décrit si bien le prix Nobel d’économie Daniel Kahneman dans son livre sur les deux vitesses de la pensée [Kahneman 2011]1.
Notre travail de recherche a donc consisté à regarder si une approche par intelligence artificielle, à la fois plus robotique, ou plus systématique suivant la terminologie de la gestion d’actif, pouvait aider les gérants d’actifs et ainsi créer le gérant augmenté de demain. Nous avons notamment examiné et développé des modèles d’intelligence artificielle autour de l’apprentissage par renforcement profond (Deep Reinforcement Learning - DRL). L’apprentissage par renforcement est l’une des trois grandes familles d’apprentissage automatique utilisées en intelligence artificielle. Ce type d’apprentissage automatique est différent de l’apprentissage dit supervisé qui consiste à « superviser » ou encore piloter, guider la machine, pour retrouver des bonnes réponses. Le cas d’école est celui de la reconnaissance d’image partant d’une base importante d’images de chiens et de chats préalablement classées. L’apprentissage supervisé consiste à trouver la relation entre les pixels des images et la catégorie de l’image, chien ou chat. Comme il s’agit d’une fonction non linéaire relativement complexe, il a fallu attendre les années 2012-2015 avec les progrès des réseaux de neurones profonds et les couches de convolutions pour atteindre un niveau équivalent à l’humain. Les réseaux de neurones convolutifs s’inspirent de façon imagée du cortex virtuel, et tentent de reconnaitre une image en comprenant quels sont les éléments essentiels (yeux, bouche…), et en les observant dans leur globalité. Le réseau va pondérer les pixels par importance, en trouvant les poids dits de convolution par des méthodes d’optimisation par descente de gradient. Par exemple, le réseau de neurones va trouver que les yeux sont essentiels pour reconnaitre un visage, le rouge pour un camion de pompier, etc…
Dans le cas de la finance, nos travaux de recherche ont précisément consisté à examiner si ce type d’architecture initialement développés pour la reconnaissance d’image pouvait aussi donner de bons résultats en finance. Les données ne sont pas des pixels, mais des données de marché, prix, rendements, volatilité, … Le réseau va trouver les données essentielles et faire le lien entre elles afin de définir un schéma répétitif entre ces données de marchés et leur évolution future. À la différence de l’apprentissage supervisé qui fournit à la machine la vraie solution, l’apprentissage par renforcement consiste à donner un état du monde et trouver par des techniques d’optimalité de Bellman l’allocation optimale en fonction de ces données de marché. La machine apprend en tirant parti de l’expérience répétée. Ce type d’apprentissage est beaucoup plus proche de la façon d’apprendre à parler d’un enfant qui par le biais de boucles de rétroactions (ou de renforcement) de ses expériences va peu à peu trouver par lui-même les règles gouvernant le langage. Même si ce type d’apprentissage machine est encore relativement peu exploité dans l’industrie par rapport à l’apprentissage supervisé (qui représente à lui-seul près de 90 % des applications pratiques actuelles), l’apprentissage par renforcement à l’aide de réseaux de neurones profonds a acquis ses lettres de noblesse lorsque les équipes de recherche de Google ont réussi grâce à ce type d’apprentissage machine à battre au jeu de Go le meilleur joueur humain [Silver et al 2017] ou encore lorsque les équipes de recherche de Facebook ont elles aussi battu les meilleurs joueurs humains de poker.
Nous nous sommes donc attachés à examiner si ce type d’apprentissage pouvait apporter une réponse convaincante à la gestion de la crise. Dans notre article en anglais « Détecter et s’adapter aux crises grâce à l’apprentissage par renforcement profond et des données contextuelles » [Benhamou et al 2020]2 ; nous montrons expérimentalement que ces techniques nouvelles peuvent détecter relativement rapidement des contextes de crises et ainsi fournir aux gérants d’actifs des outils pour éviter les biais émotionnels et réagir rapidement. L’importance de la qualité des données contextuelles est à souligner. Nous examinons des stratégies combinant des positions sur les marchés actions et obligataires. Nous fournissons donc parmi les données contextuelles des informations sur les corrélations entre les marchés obligataires et actions (à court et moyen terme), des indices d’aversion aux risques, de surprise économique comme le Citigroup economic surprise index ou encore des indices de volatilité implicite dont l’aspect prédictif de crise est largement documenté dans la littérature financière. Nos contributions sont multiples. Nous expliquons en premier lieu pourquoi cette approche par renforcement profond basée sur des données contextuelles avec une architecture de réseau profond composée de deux sous-réseaux (le premier tenant compte des performances passées, le second des données de contexte financier) permet de mieux réagir aux situations de crise. Nous montrons en second lieu que le choix de la récompense dans l’apprentissage par renforcement n’est pas neutre et qu’un critère de récompense à base de risque (comme le ratio de Sharpe ou encore de Sortino) conduit notre agent à prendre moins de risques au détriment de sa performance globale. Nous trouvons aussi empiriquement que les couches de convolutions fonctionnent mieux que des couches LSTM car les couches de convolutions permettent de mieux détecter des motifs implicites. Enfin, nous trouvons qu’avoir une dépendance entre l’allocation actuelle et l’allocation précédente n’améliore pas les modèles d’apprentissage par renforcement. Comme le montre le graphique 2, le portefeuille géré par IA, en rouge et dénommé Deep RL, a un risque réduit et une meilleure performance que 3 portefeuilles de référence en bleu, jaune et vert, ainsi que des allocations basées sur des critères financiers classiques comme celui de Markowitz en rose clair et foncé, grâce à une réduction de l’exposition aux marchés actions au début de la crise de la Covid-19 puis un retour à l’exposition initiale à compter de mi-mai 2020.
Graphique 2
Portefeuille Deep RL et méthodes financières classiques
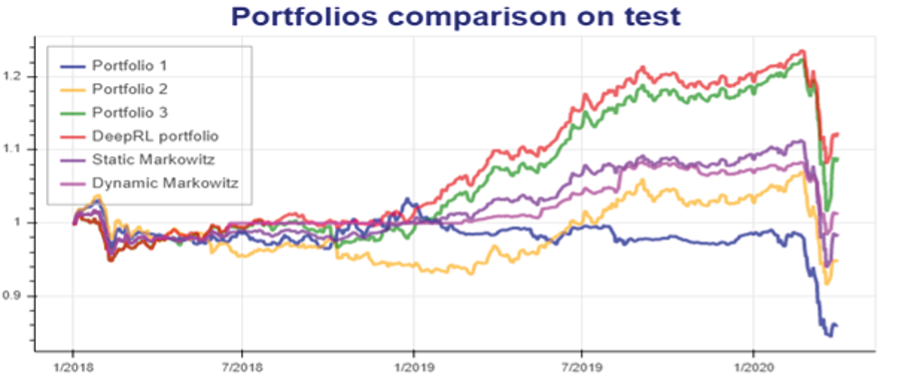
Bien entendu, ces premiers travaux de recherche n’ont qu’une valeur expérimentale et ne démontrent en aucun cas la fiabilité absolue de ces nouvelles méthodes. Cependant ils montrent que l’IA et en particulier l’apprentissage par renforcement à l’aide de réseaux de neurones profonds peut fournir des outils d’aide à la décision précieux permettant aux gestionnaires d’actifs une meilleure réactivité dans des contextes de crise comme celle récente de la Covid-19.
Ce contenu est publié sous licence Creative Commons ![]()
![]()
![]()
![]()
Nos articles sont publiés sous licence Creative Commons. Leur réutilisation est autorisée sous certaines conditions.
Notes & Références
- Kahneman, D. 2011. Thinking, Fast and Slow. New York: Farrar, Straus and Giroux.
- Benhamou E, Saltiel D., Ohana JJ et Atif J. 2020. Detecting and Adapting to Crisis Pattern with Context Based Deep Reinforcement Learning, Arxiv, et SSRN, Septembre 2020.
À lire aussi

Transition Écologique & Sociale
Politique industrielle et technologies bas carbone : la trajectoire chinoise
La domination chinoise dans les technologies bas-carbone est souvent présentée comme une conséquence de sa puissance manufacturière. Elle est avant...

Transition Écologique & Sociale
Matières premières : entre conflits sociaux, environnementaux et géopolitiques
Du cuivre des puces d’intelligence artificielle au nickel des batteries de voiture électrique, les métaux sont au cœur des transitions actuelles. Et...

La transition énergétique est parfois présentée comme une opportunité pour redynamiser l’économie française, tout en permettant de répondre aux défis...